Why Multiple Models Matter: GitHub Copilot CLI's Subagent Architecture
Discover how GitHub Copilot CLI uniquely enables parallel multi-model workflows through subagents, reducing blind spots and improving code decisions—all while maintaining cost efficiency.
If you’ve ever had an AI code review that missed something obvious, or gotten a plan that seemed solid until implementation revealed hidden assumptions, you’ve encountered the blind spot problem. Every model—even the best ones—has blind spots. The real question isn’t which model is perfect. It’s how do we mitigate what any single model will miss?
GitHub Copilot CLI introduced a compelling answer: run multiple models in parallel and consolidate their insights.
🤖 The Problem: Every Model Has Blind Spots
Let me be direct: there is a broad consensus that GPT-5.4 and Claude Opus 4.6 are both very strong models. But even the strongest models still have blind spots, and they fail differently. They have different training biases, different reasoning patterns, and different edge cases they overlook.
When you ask a single model to review your code, you’re getting one lens. That lens might miss what another lens would immediately catch. It’s not that one model is “better”—it’s that different models will catch different things.
The old approach: pick the best single model and hope it catches everything.
The new approach: run multiple models in parallel, have them review the same code/plan, and consolidate their findings.
This is exactly what Copilot CLI’s subagent architecture enables.
🎯 Spawning Parallel Reviews with Different Models
Imagine you want a comprehensive code review. Instead of running a single model and getting one perspective, you can do this:
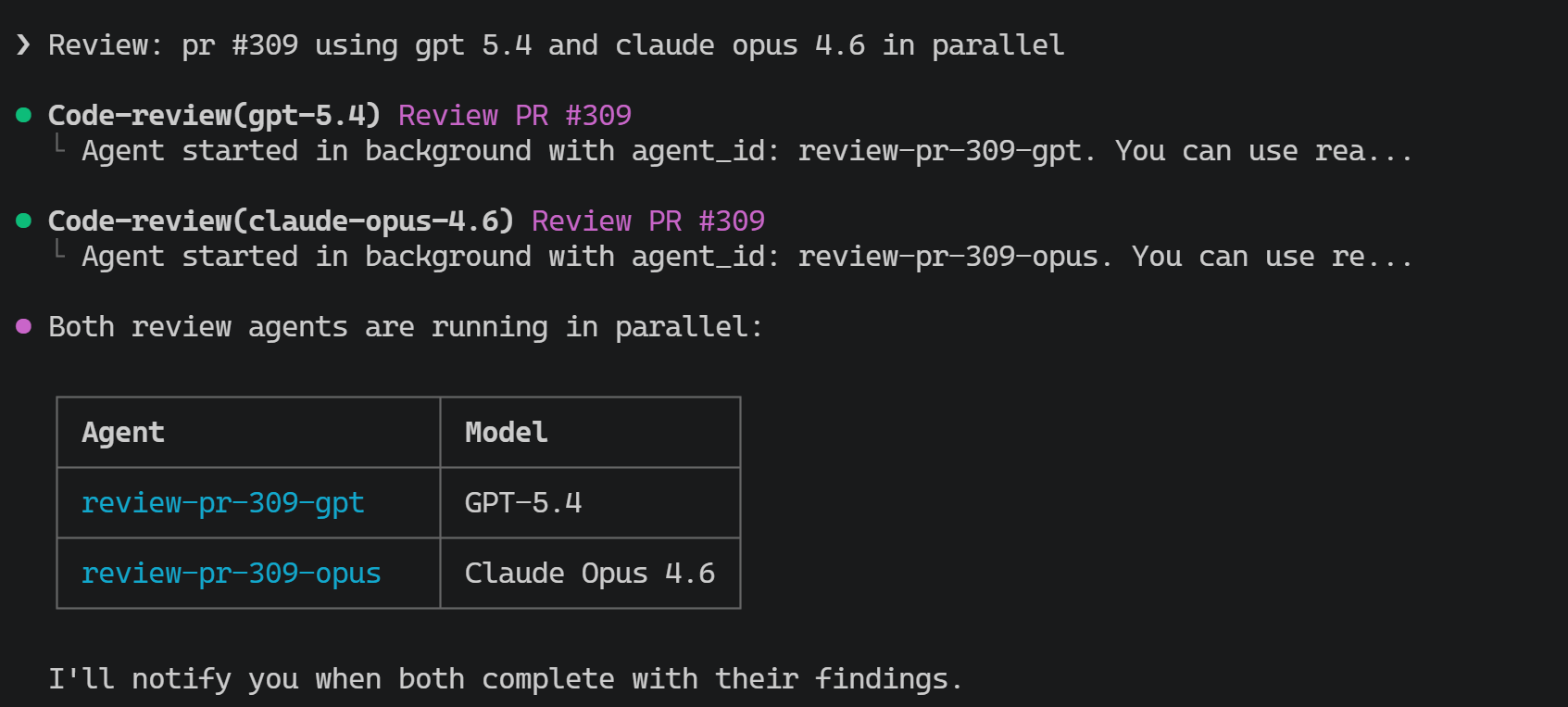
/review pr #309 using gpt 5.4 and claude opus 4.6 in parallel
The screenshot below shows the two review agents running in parallel and waiting for the consolidated result:
 Here’s what happens:
Here’s what happens:
- Parallel Execution: Copilot CLI spawns two independent subagents simultaneously. One uses GPT-5.4, the other uses Claude Opus 4.6.
- Independent Analysis: Each model reviews the same pull request without seeing the other’s feedback. Each brings its own training, reasoning patterns, and blind spots to the table.
- Consolidation: The primary Copilot CLI agent synthesizes the findings. It identifies overlapping concerns (high confidence issues both models flagged), unique insights from each model, and presents a unified review that’s richer than either model running alone.
The magic isn’t that you’re getting two reviews to read separately. It’s that Copilot CLI intelligently merges them—surfacing what each model caught that the other might have missed, while eliminating redundancy.
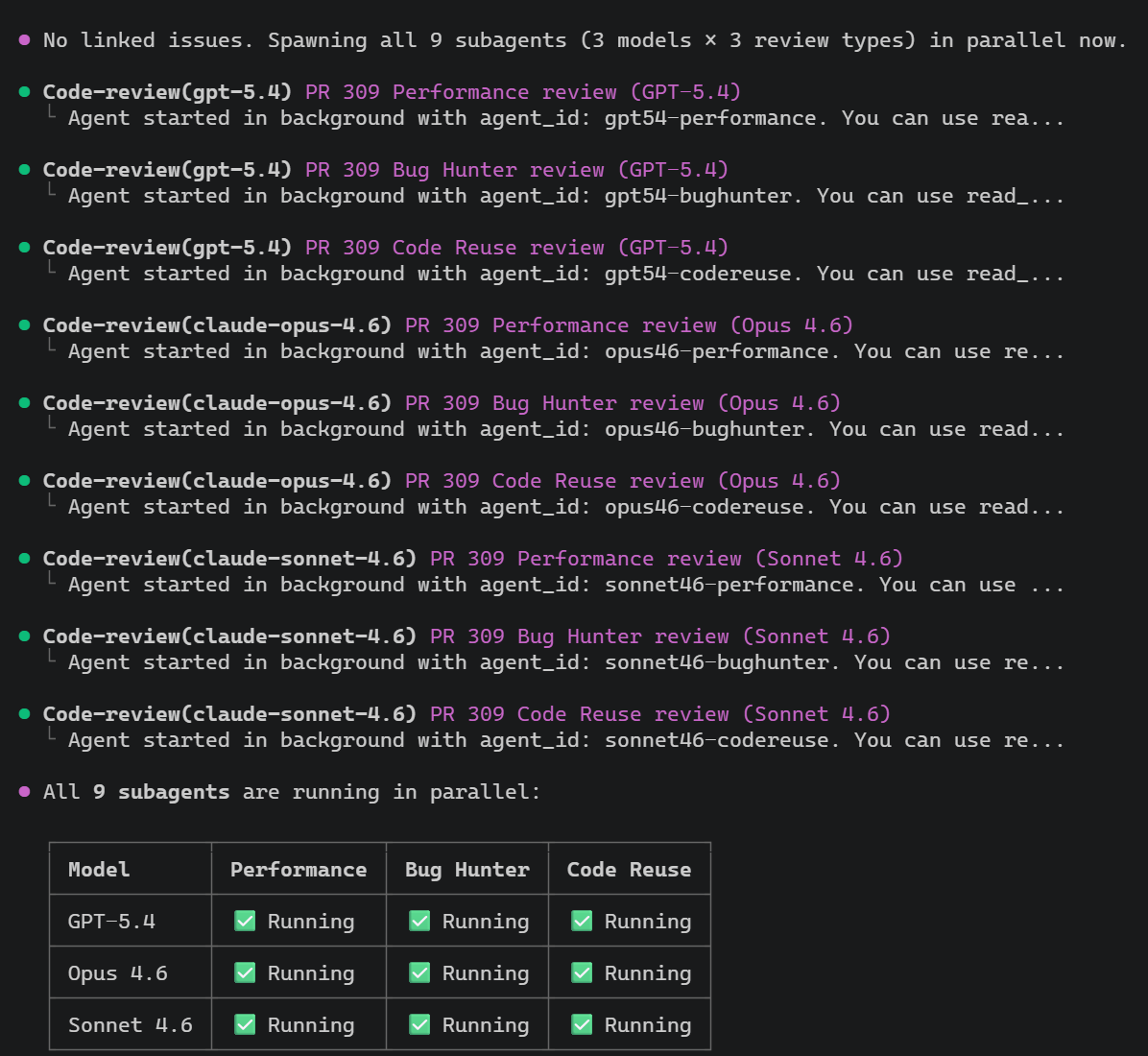
And this is not limited to two models. I also built an al-code-review skill that asks for three review angles—Performance, Bug Hunter, and Code Reuse. A prompt like review pr #309 using gpt 5.4, opus 4.6 and sonnet 4.6 with the al-code-review skill can fan out into 9 subagents: 3 models × 3 review angles. That is where Copilot CLI gets especially interesting: you can stack model diversity and review diversity at the same time.
The screenshot below shows all nine subagents running in parallel across the three models and three review angles:
Why This Matters
Different models catch different things:
- One model might identify a subtle race condition another overlooks
- One might flag a maintainability issue the other glosses over
- One might recognize a security concern another didn’t consider
- One might spot an architectural assumption that breaks under scale
By running models in parallel, you get broader coverage. You reduce the probability that a critical issue falls into the blind spot gap all individual models would have independently missed.
📋 Combining Planning with Validation
The /review approach is powerful for retrospective analysis. But what if you could combine planning with live validation?
/plan add the option to only allow sales orders to be edited by the currently set sales person. before presenting the plan do a review of it using gpt 5.4
This workflow:
- Generates a plan for implementing the feature
- Automatically triggers a review of that plan using GPT-5.4
- Incorporates feedback before presenting the plan to you
Why? Because a plan is where early decisions compound. A flawed architectural choice made in the plan stage becomes a foundation you’re building upon. Catching it early costs far less than discovering it mid-implementation.
This command shows a critical capability: workflow composition. You’re not just running isolated commands—you’re chaining them with conditions and logic. “Generate the plan, then have another model review it, then show me the refined result.”
🦆 Rubber Duck: Automatic Second Opinion (Experimental)
GitHub Copilot CLI recently introduced an experimental feature called Rubber Duck. It takes the multi-model concept and makes it even smarter: automatic second opinions at critical checkpoints.
When you’re using a Claude model as your primary orchestrator, Rubber Duck leverages GPT-5.4 as an independent reviewer. Unlike manual multi-model commands, Rubber Duck activates automatically at key decision points:
- After drafting a plan: Before implementing, get a second opinion on whether the approach is sound
- After complex implementations: Have a fresh perspective review intricate code before moving forward
- After writing tests, before executing: Catch gaps in test coverage or flawed assertions
- Reactively when stuck: If the agent hits a wall, Rubber Duck can break the logjam
According to GitHub’s recent evaluations, Claude Sonnet paired with Rubber Duck closes 74.7% of the performance gap between Sonnet and Opus running alone. On difficult multi-file problems spanning 3+ files, Sonnet + Rubber Duck scores 3.8-4.8% higher than Sonnet alone.
Real examples Rubber Duck caught:
- Architectural issues: Proposed code that would start and immediately exit without running
- Silent data loss: A loop that overwrote the same dict key, silently dropping results
- Cross-file conflicts: Code that stopped writing to a key that other files still read from
Rubber Duck is available now in experimental mode via /experimental in Copilot CLI.
💰 The Cost Story: Pay Per Request, Not Per Subagent
Here’s the financial elegance: Copilot is charged per user request, not per spawned subagent.
When you run /review pr #309 using gpt 5.4 and opus 4.6, you’re making one request to Copilot. The fact that it spawns two parallel subagents doesn’t double your charges.
This means:
- Run three models in parallel for near the cost of running one
- Experiment with Rubber Duck’s automatic reviews without per-review costs
- Compose complex workflows (
/plan → validate → review → refine) with predictable per-request pricing
It’s a powerful incentive structure: the system encourages you to leverage multiple perspectives because the marginal cost of doing so is minimal.
📐 Why This Changes How You Work
The traditional mindset: Pick the single best model and use it well.
The new mindset: Compose models strategically to mitigate blind spots and catch what any individual model would miss.
This isn’t about having unlimited compute. It’s about recognizing a fundamental truth: different AI models have different blind spots. Running them in parallel and consolidating isn’t complexity—it’s just being thorough.
For high-stakes tasks—architectural reviews, security-critical code, major refactors—this approach pays for itself in reduced rework and caught issues. For routine work, it’s still faster than manual review and catches things you’d likely miss alone.
🚀 Getting Started
If you use GitHub Copilot CLI:
- Try multi-model review:
/review pr <number> using gpt 5.4 and opus 4.6(adjust model names as available) - Chain commands with conditions:
/plan <feature> before presenting the plan do a review using gpt 5.4 - Enable Rubber Duck (experimental): Use
/experimentalto activate automatic second opinions - Observe the consolidation: Pay attention to how Copilot merges insights—what did each model catch?
For developers new to Copilot CLI, this architecture is worth understanding because it fundamentally changes how you should think about AI assistance. You’re not delegating to a single expert. You’re orchestrating multiple perspectives to make better decisions.
The blind spot problem doesn’t go away. But with subagents and intelligent consolidation, it becomes something you can systematically address.
Curious about how Copilot CLI orchestrates these parallel reviews? It uses the same subagent infrastructure that powers /review and /plan commands. The elegance is in the composition: leverage multiple models, consolidate findings, present a unified result—all within a single user request.
Want to explore this further? Check out GitHub’s official Rubber Duck announcement for technical depth and benchmark results.